
eroshko.md 13 KB
Методы, способы и средства обеспечения отказоустойчивости автоматизированных систем
Что такое отказоустойчивость и стабильность?
Под отказоустойчивостью будем понимать свойство системы, которое позволяет максимально сохранять работоспособность при отказе отдельных конкретных компонентов системы либо связанных систем и восстанавливать работоспособность системы при восстановлении отказавших компонентов или связанных систем. Давайте рассмотрим подробнее эти 2 момента:
Деградация работоспособности системы должна быть прямо пропорциональна "величине" отказа. То есть, если упал сервис, отвечающий за некую некритичную функциональность — вся система не должна при этом падать. Да, небольшой кусочек не работает, но это не влияет на стабильность остальной части функционала.
Стабильность системы предполагает самостоятельного восстановления работоспособности после сбоя как компонентов системы, так и всей системы в целом. К примеру, если пропадала сеть на некоторое время — то у стабильных систем после восстановления подключения все компоненты продолжат работать и данные вернутся в консистентное состояние без ручного вмешательства со стороны команды эксплуатации.
Наглядное сравнение
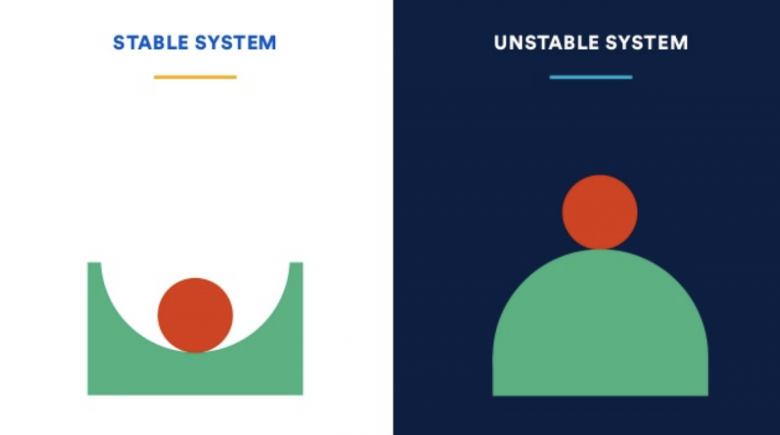
Если в стабильной системе из нормального состояния равновесия шарик в центре чуть-чуть подтолкнём в сторону — он, конечно же, ненадолго отклонится от равновесия (т.е. система перейдёт в некоторое неидеальное состояние), но после этого шарик быстро вернётся в нормальное состояние. В случае же плохо спроектированных и построенных систем — даже лёгкого воздействия на шарик достаточно, чтобы система начала деградировать с нарастающей скоростью. При этом сам по себе шарик не вернётся в нормальное состояние в таких системах.
Как измерить отказоустойчивость и стабильность?
Но как же определить является ли наша система отказоустойчивой и стабильной? И на сколько? Как в идеале замерить эти свойства, чтобы двигаться к цели согласно некой метрике, а не наощупь?
Единственный способ спроектировать систему, которая будет устойчива к сбоям — проводить стресс-тесты (resilience testing / chaos engineering), по результатам тестов делать выводы, менять архитектуру и подходы к написанию кода, снова запускать тест... и так до бесконечности :)
Количество пройденных тестов и будет метрикой отказоустойчивости отдельных компонентов и системы в целом. Только на основе метрики делаем вывод о повышении или понижении стабильности системы.
Создание таких тестов — уже непростая инженерная задача. Для начала необходимо описать и автоматизировать сценарии отказа (легла сеть, закончилось место на диске, внешний сервис отвечает ошибками, сеть тормозит или доставляет только 50% пакетов, выключилось электричество на конкретном физическом хосте или во всё дата-центре и т.д.) — а потом запускать их в произвольном порядке, да и ещё и в случайных комбинациях друг с другом ??. Тесты позволят нам и получить измеримую метрику (прошли 10 тестов из 50), и понять какие отказы наиболее критичны, т.к. сразу же приводят к краху всей системы.
Принципы построения отказоустойчивых систем
Отсутствие единой точки отказа (No SPoF - Single Point of Failure)
Принцип применим ко всем уровням эксплуатации — от точки деплоя (любой Nginx или микросервис в системе) до уровня дата центров. Рассмотрим этот принцип на примерах репликации и балансировки небольших компонентов системы:

Для его реализации сервисы должны быть готовы к запуску в нескольких экземплярах — как минимум не должны хранить состояния (быть stateless-сервисами). Давайте рассмотрим обратный пример, когда у нас сервис хранит состояние и неготов к горизонтальному масштабированию. Пусть в нашей схеме сессия пользоавтеля хранится на самом бэкендовском сервисе:

Проектирование с учётом отказов (Design for Failure)
В любой системе происходят отказы и падения, поэтому важно уже на этапе проектирования архитектуры держать в уме, моделировать и закладывать обработку нештатных ситуаций. Рассмотрим основные базовые идеи концепции:
Постепенная деградация (Graceful degradation) — это возможность частично деградировать функционала системы в случае отсутствия/неработоспособности её компонентов. Рассмотрим на схеме вариант построения системы с последовательной связанностью и полной деградацией при отказе:

Другой вариант частичной деградации — потеря или отложенное предоставление некритичных данных. Например, мы можем показать позже срок доставки товара (или не показывать вовсе) в случае проблем с компонентом расчета доставки, при этом вся остальная информация и возможность купить будут доступны.
В худшем варианте, если некий BFF или API Gateway дожидается синхронного ответа от каждого компонента и только потом отдаёт результирующий html — страница отобразится пользователю только после отрабатывания самого медленного компонента (или суммы времени всех, если запросы строятся ещё и последовательно, а не параллельно). При падении одного из компонентов (например, не самого важного раздела с похожими товарами) в нетолерантном к отказам варианте проектирования пользователь бы в принципе ничего не увидел кроме страницы с ошибкой.
Помимо отложенной доставки или потери данных, в случае их критичности — можем деградировать в их актуальности взамен полного отсутствия при помощи кэширования. К примеру, если источник актуальных данных недоступен — берём предсохранённые данные из кэша: в зависимости от сценария, тут может быть как частичная деградация (актуальные данные лучше старых, но старые лучше их отсутствия) так и отсутствие деградации вовсе (пусть в 99% случаев закэшированные данные соответствуют актуальным).
Выводы
На основе рассмотренных принципов и подходов можно сформулировать следующие ключевые выводы:
Основные положения
- Отказоустойчивость и стабильность — взаимосвязанные, но различные свойства системы, требующие целенаправленного проектирования и тестирования
- Отказоустойчивость обеспечивает постепенную деградацию функциональности при отказах компонентов
- Стабильность гарантирует самостоятельное восстановление системы после сбоев
Методология оценки
- Единственный эффективный способ оценки — стресс-тестирование и chaos engineering
- Количество пройденных тестов служит объективной метрикой отказоустойчивости
- Автоматизированные сценарии отказа позволяют выявить наиболее критические точки системы
Архитектурные принципы
Отсутствие единой точки отказа — фундаментальный принцип, требующий:
- Stateless-архитектуры сервисов
- Готовности к горизонтальному масштабированию
- Репликации критических компонентов
Проектирование с учётом отказов — включает:
- Реализацию постепенной деградации функциональности
- Стратегии обработки частичных отказов (кэширование, отложенные данные)
- Параллельную обработку запросов вместо последовательной
Практические рекомендации
- Критически важные данные должны быть доступны через кэширование при недоступности источников
- Некритичный функционал может временно деградировать без влияния на основную систему
- Архитектура должна допускать частичные отказы без полного прекращения работы
Непрерывный процесс
Создание отказоустойчивой системы — итерационный процесс, включающий:
- Регулярное тестирование на устойчивость к сбоям
- Постоянное совершенствование архитектуры
- Анализ метрик и адаптацию к новым угрозам
Только комплексный подход, сочетающий продуманную архитектуру и регулярное тестирование, позволяет создать действительно стабильную и отказоустойчивую систему.
Источник: habr.com